This notates the initial goals and architecture of my Portal.js library, as well as the challenges faced while creating it. Although a simple premise considering the already created system of vdo.ninja, this library had some deep roots in peer-to-peer (p2p) networking, asynchronous code design, and asymmetric-encryption.
Introduction
Portal.js is a JavaScript library which creates a synchronized database between browser pages. Specifically, Portal creates a simple key/value database, which is synchronized with other users of the library (who are in the same channel). It is fully p2p based, meaning there aren't any servers facilitating the database syncing. As well, it's open source (GPL-3.0) and free for use.
The reason Portal.js was created in the first place was out of need for a synchronized database for a web-based software called Vidlium. In the software, admin-style users are able to edit data, which public users can then read some of (but distinctly not write to any of it). Now I had hacked together a quick solution before this, however, this library represents a cleaner, more featured, and fully buttoned up solution. Vidlium provides the design requirements for Portal's design, so I came back to Vidlium many times during the project. And although designed specifically for Vidlium's use case, I wanted to make this library general enough that others can make use of it.
In this writing, I will:
- Lay out the initial goals of the project
- Discuss the Architectures used in Portal.js
- Including the challenges faced with those choices
- Explore how encryption was used in Portal.js
- Including the challenges faced with that technology
- Wrap up with some closing thoughts and joys of the project
Initial Goals
As mentioned, I had created a super-bare-bones version of a syncing system before this. And so when choosing to redesign and solidify it, I knew I needed to keep it simple. I rarely worry about running out of things to add, and because synchronizing and networking systems can get complex quick, so I knew well-defined goals were needed.
- Keep as simple as possible. Keep the whole system simple, but especially the interfaces, because I want others to be able to use it.
- Use VDO.ninja for P2P. I don't want to spend money on and/or be reliant on servers I have to keep running into the future.
- Documentation for days. Others and I should be able to find, fix, and add things easily.
- Have reasonable security. I am not a security professional, but I should design a reasonably safe system.
Messaging Architecture
When planning out how to make Portal.js work, I was faced with a choice of what architecture of communication I should put effort into using. Largely, there exists 2 styles of managing messages between people on the internet: Server-client, and Peer-to-peer (p2p).
P2p is an architecture where instead of having a central server all users talk to, all users talk directly to all or some other users directly as peers (see diagram 1). Server-client architectures rely on a central server to receive and pass on messages to other users.
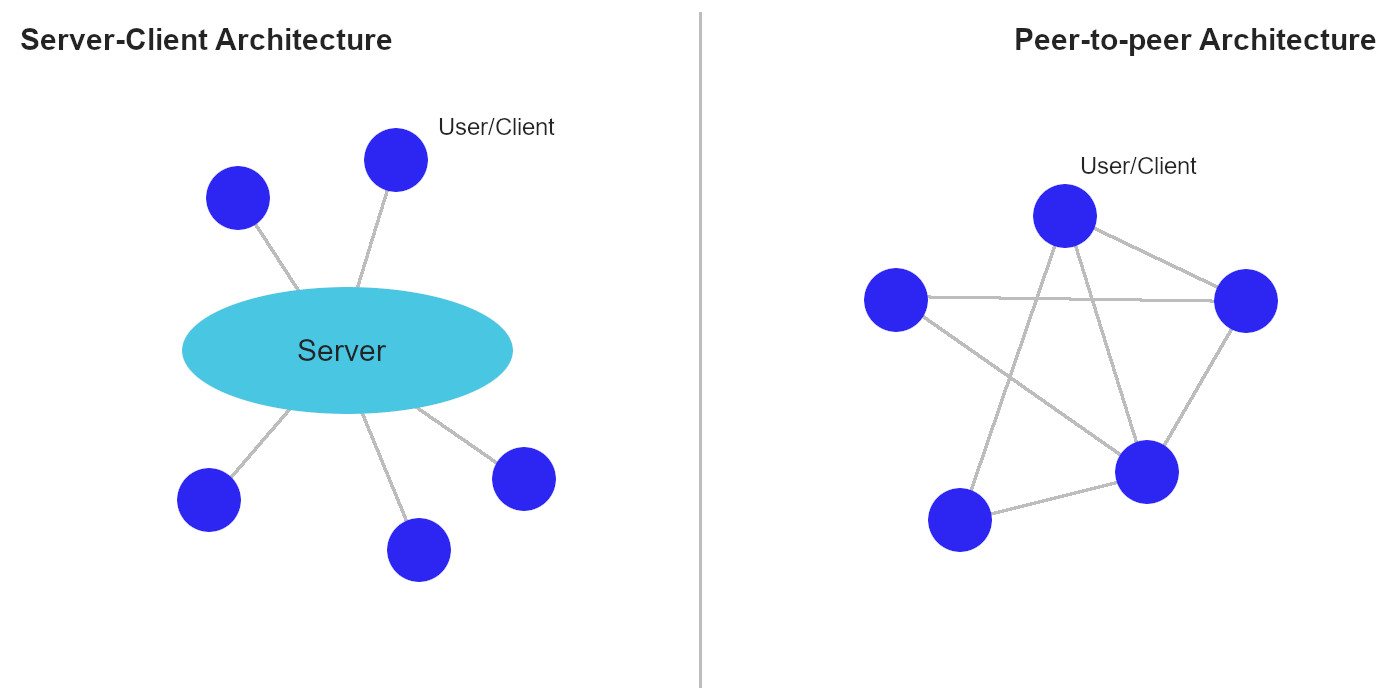 *(Diagram 1) Displaying communication structure differences between Server-client and Peer-to-peer models.
*(Diagram 1) Displaying communication structure differences between Server-client and Peer-to-peer models.
A p2p system can reduce the need for servers, which is good for my 2nd goal. But it's important to note that no matter what, there needs to be "handshake" servers somewhere to initially handle communications. P2p systems just uses lighter weight handshake servers initially to connect users, and then from then on users talk directly. Furthermore good p2p systems should have "STUN" and "TURN" servers for network traversal and fallbacks.
Furthermore, a p2p system trades the addition of central servers for the complexity of client side code having to manage many different connections. Meaning more code is needed, which is bad for my 1st goal of keeping things simple.
Although, a p2p style system still needs servers in the end and can be rather complicated in code... I chose to build Portal.js on a p2p architecture. I was enabled to do this because there is already a p2p communication system that removes the server-hosting and some complications: VDO.ninja. Built by Steve Seguin, a super smart guy who knows 10 times as much about WebRTC and p2p systems, VDO.ninja has already done a lot of the hard work for me and has a nice Iframe API to use it. Plus, it is a well established and utilized system that is regularly updated, meaning less work on my end to stay up to date.
I have previously used VDO.ninja in Vidlium, and I have contributed to its development. So I was a little biased in my choice of using it. But I did seriously consider a server-client based solution like Firebase or Supabase, however, I or others who use this library could run into issues with free caps (and I don't want to spend any money on this).
The channel structure
In portal.js, each user using the system can open a shared 'channel'. In a channel, all users (I will also refer to them as peers) can talk to each other directly: creating a web of communication. Channels are only delineated by an ID, so as long as the ID is long and complicated, and the system which shares the channel ID's to peers to join through is secure, its unlikely anyone will stumble upon the channel (Goal #4).
For Vidlium, there are actually two channels used at a time: one for admin-style users, and another for the public. For example, an admin-style user will have a webpage that opens two channels A and B. Channel A will be able to sync data1, data2, and data3 values to others in that channel, and channel B will only share data1 with others in that channel. Public users will have webpages that can only open channel B, and thus the public users they only see and sync data1. In this way, channels are just a way of structuring access to certain data.
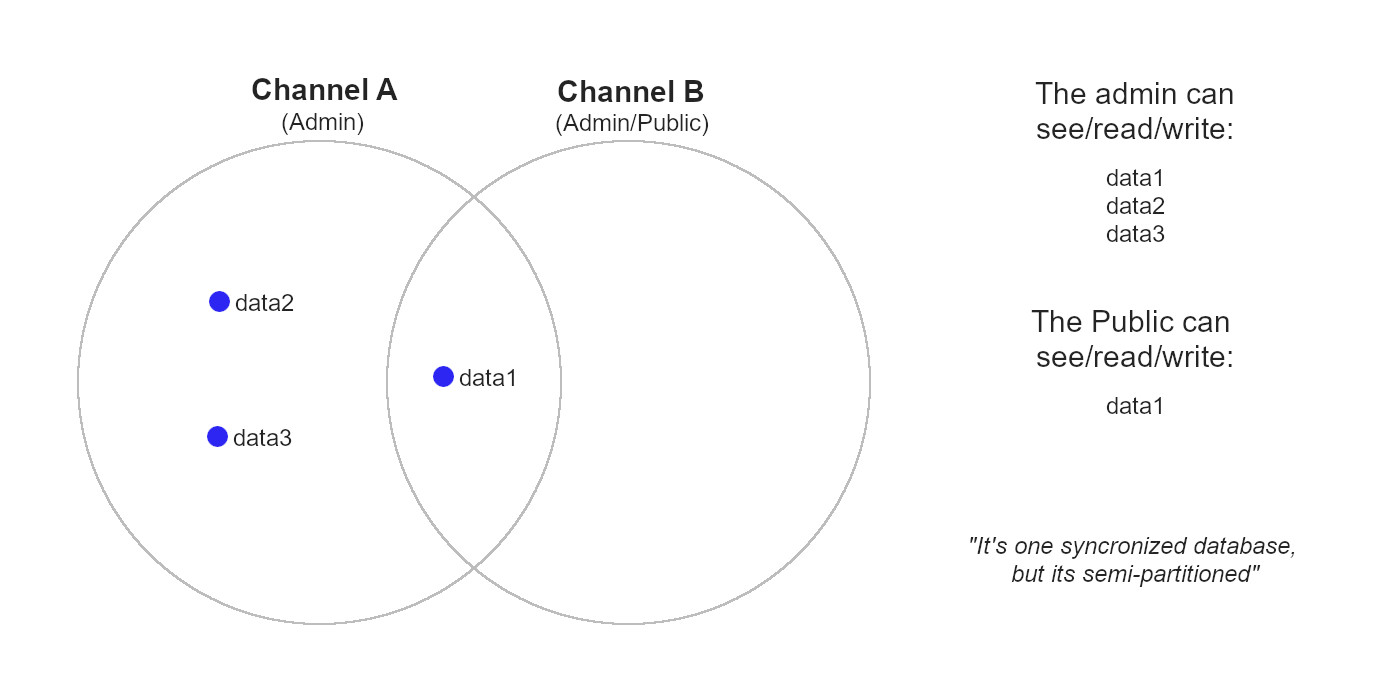 *(Diagram 2) Displaying organization of two channels' access to data.
*(Diagram 2) Displaying organization of two channels' access to data.
However, this channel system does splinter the notion of having a singular shared database. In fact, for more complex arrangements of channels, it is easier to think of the system as a venn diagram of databases. Users can have any number of channels open, and for example there could be a channel C that all public users in also join (containing data4 and data5). In this case, the public users could have their databases consist of data1 as well as data4 and data5.
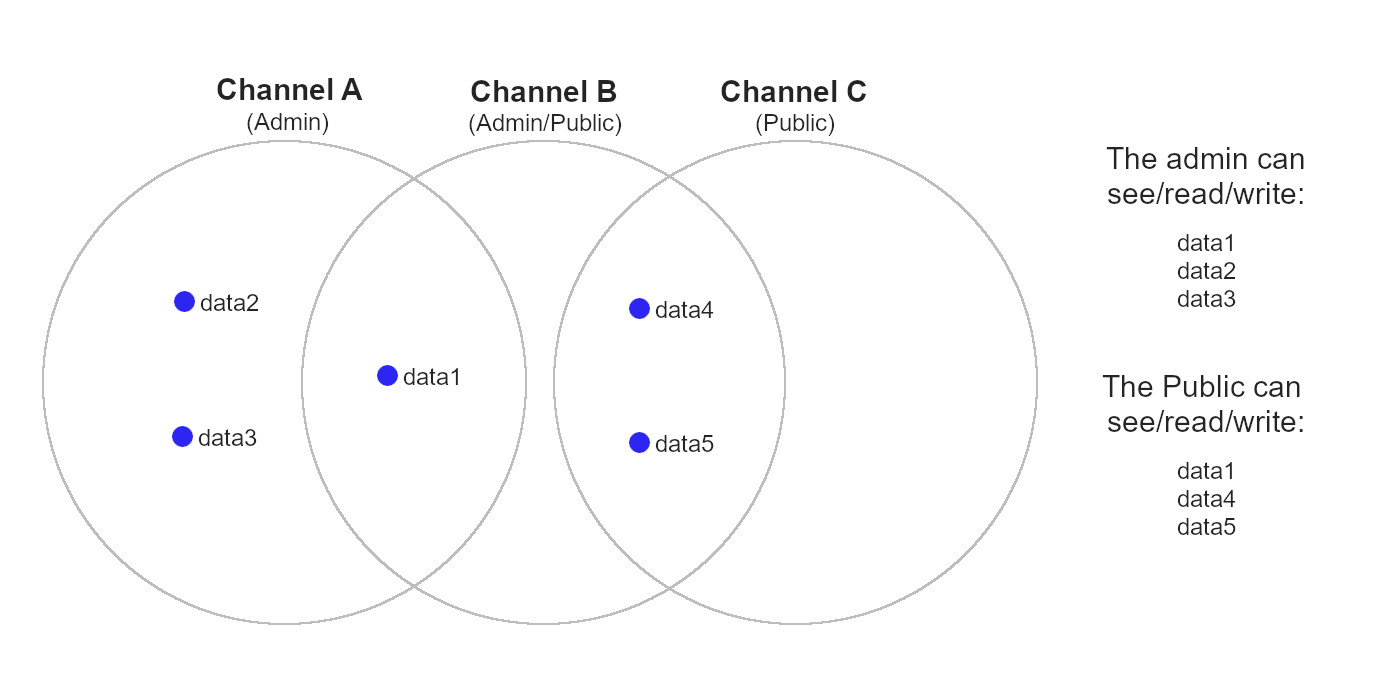 *(Diagram 3) Displaying organization of three channels' access to data.
*(Diagram 3) Displaying organization of three channels' access to data.
The choice to use a channel structure was a hard decision to make. I could have just as well had a portal be only be a manager of syncing data in a singular channel, leaving the database and access system (probably through multiple portal instances) on the developer using the library. However, because I was also the developer using the library in Vidlium, and I was going to do that anyway, I chose to include those systems in the library. And having a singular database with the complexity of channels managed by the library itself aids itself to more complex things, like adding read-only-data (see the encryption section below).
How to sync values
In my initial (hacked together) precursor of this library, I made it so anyone who made a change to a value would simply push the changes to all the peers connected, and called it good. In reality, you need a more sophisticated system of managing changes to values so that you don't get peers out of sync.
Some questions needing to be solved with syncing changes are:
- How do they know if the changes they are making are propagating to all the peers?
- How to deal with sync conflicts where peers have different values.
- What happens if some peers are disconnected, or are new peers joining without any current values.
Well, I am not the only one who has tried to figure out a consensus of values between many peers. An already created algorithm called RAFT does a good job of solving this. However, it is rather complex with a system for an elected leader for pushing changes, and I only need a few parts of it for inspiration.
Specifically, I took a page from the RAFT book with a "push request" system. In this, peers first create a push request, and send that to all peers in channels that sync that value. Once received, a peer responds if that change can be pushed. Once all peers respond, meaning that there is good communication between all peers, a command to apply the change is made. This way, changes are only made if everyone can receive and mirror the change, solving any issues of peers not knowing if changes have propagated through the system.
One thing that needs to get implemented for the push system, is dealing with idle or otherwise un-responcive peers. If a peer regularly doesn't respond to the push requests or other pings, there needs to be a mechanism to handle removing them from the peer lists. Because otherwise we have to wait for their oush message to timeout, which slows down the system for the others.
Another thing, which I am yet to implement fully, is managing sync conflicts. The challenge is when peers have different values for the same key (which shouldn't be the case ever, but things happen...). Although not exactly the same solution, it has some similarities to RAFT. In RAFT, the system stores a list of all changes made to the values. Whereas, I will just timestamp the last changes to all key/vale pairs, and go with the most recent timestamp when comparing them. This does little to prevent bad-actors overwriting data. And the peer's clocks will need to be synced, so that somone with a bad clock doesn't get an unfair advantage in comparisons. But I belive this will be a good-enough solution for a small passion project.
The final challenge with syncing values is how to update peers who don't have any of the current values. I didn't take any inspiration from RAFT for this, but only because its a simple solution: I let peers request the full database when they join/rejoin. As part of this, they need to make requests to multiple people to, one, trust that the data is valid, and two, recive all the data from all of the channels they are in.
Using Object-Oriented Programming
Object-oriented programming (OOP), for the uninitiated, is a style of programming where you can define classes of code which -- once instantiated -- are portable, consolidated, and convenient objects. I am proud of the OOP structure created in the Portal.js library, because it allows complex and asynchronous communications to be made, with a simple interface to use from within the library.
I want to highlight two classes for objects I created:
- a
pushRequestclass, which manages conversations specifically for updating values. - a
conversationclass, which manages call and responses between peers.
When a change is trying to be made to a value, Portal.js creates a new pushRequest which then creates multiple conversation's with other peers. Both pushRequest's and conversation's are very asyncrounous bits of code. A push request first checks what peers to send the push too, then signs the request, and starts conversations to send the push. Now the conversation objects talk with individual peers, managing what messages from them are part of the specific conversation, and returning the responce heard. Once the pushRequest object has heard from all the peers it sent messages to, it sends the the complete-request command for the peers to execute the change on their ends. And to initiate this complex system, all I have to do is say new PushRequest(id, key, data).sendToPeers();and a push request does its work. And all a pushRequest has to do is say .send({"push": {...}}, (responce) => {...}); in the code, and the conversation object handles all the low-level asyncrounous interations with VDO.ninja. Just like that!
In reality, a conversation directly interacts with the Iframe API in VDO.ninja. Formats, and signs, any messages with authentication (see the encryption section below). Asynchronously waits for responses for it specifically to come back. And manages calling the callback once the correct response is recived.
Furthermore, a pushRequest itself has some complex code, which is all accessible by just saying new PushRequest(id, key, data).sendToPeers();
In reality, a pushRequest first computes which peers in which channels to send the update too. Sends those peers push messages, which they should respond to. As peers all respond, it checks if enough have responded to complete the push request. Has checking for dormant peers who don't respond to anything. And sends complete-request command before updating the local database.
Encryption
- Needed some authentication for messages
- Initially using subtleCripto
Challenges (with encryption):
- Scared of it
- Only works because the join url is trusted.
- Needed library with short enough length
Closing thoughts
I was the client for this library. I need it for syncing dashboards live between users in another one of my projects: a software called Vidlium. Its a personal project, and so I had leniency and bias over constraints, but I am using it as a sharpening block for many new skills in computer science, and so treated it as professionally as possible.
The constraints
My software, Vidlium is a complex system, and as such had a few specific constraints that guided the design of Portal.js:
- It has a complex multi-channel communication structure needed to keep data secure and only let some data be public. And so Portal.js needed to handle multiple channels and levels of access for data.
- Vidlium has a separate system for transferring secrets like channel-names and auth-keys. And so Portal.js didn't need to handle transferring initial important values like that.
- The software is 100% raw HTML, JS, and CSS; no abstractions. So the library needed be structured for making the page responsive. I don't want to have to make my own separate tracking logic for managing when data updates, the Portal should handle it.
I imposed a personal constraint though, as well:
- In order to keep costs down and build in longevity -- I could not use central servers. That way, I wouldn't have any money tied into the project, and it could live without it relying on my continued support. When users need it, it can spin up and run on their hardware, not mine.
The goal
Most central function of the library: Sync data between multiple browsers. It should be particularly useful for creating real-time, collaborative web applications where data needs to be shared and synchronized between multiple peers.
The measure for success was if I could implement:
- A trustworthy syncing system -- in the case of failure of communication or loosing peers, people won't get out of sync.
- Personal peer data -- peers can have images and names associated to them.
- Secure read/write authority -- users shouldn't have to worry about people being nefarious.
- Basic failure and error handling -- users of the library can understand what went wrong when something does.
- Documentation for functions -- so I am not the only one that can use this!
- Clean object orientated and event driven code -- I better not hack uncommented things together like previous projects.
Challenges I faced
Read only data
There came a point when I had eclipsed the previous work I had done (just better this time) and started looking at when else I would want to add to the library. Read only data for specific people/channels, was on the list. It is a feature I was planning on needing for Vidlium, so that people could fully publicly read the data, while the directors could securely read and write to the data.
However, developers don't start projects because they are easy, but because we think they will be easy...
The issues with adding write/read rules is a product of the way the system is designed and secured. Lets say you have two channels, with 1 having read/write privilege's over some data and 2 only read access. In this, if a director is in both channels, you need some way of identifying that peer as being in channel 1 to accept write requests from them in channel 2.
Its important to note that the system is currently designed so that:
- Anyone can say anything in the channel to anyone, there isn't a central authority to limit messages sent.
- And you can't ask a peer what other channels they are in. This prevents a bad-actor from channel surfing, keeping channels private by default.
Those are challenges to deal with, but we do have one good thing going for us:
- If a peer has joined the channel legitimately, then they must have followed a link given to them by a director...
![[Authentication Trouble Bad Actor.png]]
Adding a central authority?
As is seen with the RAFT algorithm, you can built a central authority into a peer-based system, however this is a very bad idea to implement in Portal.js at this point. For one, a bad actor may by chance become the authority when the authority leaves. Furthermore, with the complex channel system, how would you deal with different authorities from different channels? And finally, I had already built up the system, and would rather get this done than spend another two months working on a complex RAFT based implementation.
Peer IDs?
I contemplated using some sort of ID which only the director could have. Conveniently, all the peers have UUID's I can access. I could put the UUID of those who are authorities in the URL of the join link (in this case "A"), and peers would check if the push came from the correct UUID. However, I could only put in UUID's for the directors who were active at the time, and if any other directors joined after the fact they wouldn't have authority. I could build a system where already authorized directors could authorize more directors when they join, but then if all directors leave or are disconnected briefly, the authority would be completely lost.
A simple password?
A thought I could have was a push request could come with a password. The password could be gotten from the URL of the join-link much like before with the ID's. But as seen in the diagram, peer "A" can't simply send a password as authorization, because then the bad actor "B" would receive the password the first time any push was sent to all peers in channel 2. As well, you would have to trust everyone who had the link to not be a bad actor.
You have to be able to put a password out into the open, one which can identify the director or have only came from them.
Encryption, specifically Signing and Verifying?
[!NOTE] I remember thinking about encryption, however I didn't want to consider it because it seamed like a rabbit hole. And I have heard from many sources (mostly offhandedly in answers about encryption on stack exchange) that because its so complex you might make a hole in security without realizing it. However, I realized that I needed to keep scope in mind.
I am mostly assuming that a bad-actor has stumbled upon the room, which is hopefully unlikely as its recommended in the documentation to have a long and complex ID. Furthermore, the library should stop itself from sending messages if its not supposed too, preventing most basic people fooling around with it in the inspect-element console, and a bad-actor would need to have an intentionally modified version of the library. This is really a second-line of defense, and I feel I can get good enough and feel safe with that.